brat normalization
Note: normalization features are new in v1.3 (Crunchy Frog). Please make sure you're running v1.3 or newer before attempting to set up normalization.
Introduction
The identification of the real-world entities that are referred to in text is an important part of analysing the meaning of text. Many specific task formulations that involve the association of text with entries in external resources such as ontologies and entity databases are studied, with tasks termed variously as normalization, grounding, entity linking and wikification.
As of v1.3, brat implements a number of features for supporting the visualization and manual creation of such annotations:
- Normalization annotation primitive associating brat annotations with entries in external resources
- Visualization functionality showing information from ontological and database resources
- Tools for creating, accessing and managing normalization databases
- Comprehensive annotation support for normalization, including fast approximate string search for large databases
This page briefly introduces these features and how to set brat up for the visualization and creation of normalization annotations.
Requirements
The brat normalization system uses SimString for approximate string matching. Before trying to set up brat for normalization, please install SimString (and optionally its python bindings) following the instructions on the SimString homepage. If python bindings are not installed, make sure the simstring executable path is set up correctly in the configuration file.
Quick start
If you want to set up normalization in brat using your own data, skip over this section into setup. To quickly test the brat normalization functionality on some example data, just follow these easy steps:
In the brat root directory, run the following command:
python tools/norm_db_init.py example-data/normalisation/Wiki.txtThis will create a normalization DB using a small sample of data from the English Wikipedia (generated from a Freebase Wikipedia data dump).
Next, open the tools.conf file using your favorite
text editor and add the following line to the
[normalization] section (as one line):
Wiki <URL>:http://en.wikipedia.org, <URLBASE>:http://en.wikipedia.org/?curid=%sThis tells brat that a DB with the name "Wiki" is set up for normalization and provides links to the homepage and online term lookup that will be shown in the brat UI.
Then open the annotation.conf file, and enable the normalisation for each entity and event type where it is applicable, like this:
Person <NORM>:Wiki
Family Arg1:Person, Arg2:Person, <NORM>:WikiThat's all! Now, when creating annotations, you will be able to search (a small sample of) Wikipedia from within brat and attach normalization annotations to other annotations, as shown in the next section.
Normalization annotation
After setting up a normalization database and editing
tools.conf to configure brat to use it, brat is ready
to create normalization annotations. Note that you should reload any
open brat windows for the configuration change to take effect.
When creating any annotation marking a text span such as an entity annotation, the "Edit annotation" dialog should now include an additional section for normalization:
The List button opens a list of all normalizations the that have already been added to this span, and allows adding, editing and deleting of normalizations. The parenthesised number on the button is the number of existing normalizations. To allow a new normalization to be added quickly, there is also a Quick Add button, which skips the normalization list dialog.
It is only possible to add normalizations that are configured as appropriate for the span type. If there are any normalizations already present that do not match the span type, they will be marked in the normalization list dialog with a red exclamation mark. Each normalization shows the normalization database, the ID of the normalization in that database, and the canonical name. If the normalization database has a direct URL pattern configured, the magnifier icon will open the corresponding web page. The Edit and Add buttons will open the normalization search dialog. Note that the changes to the normalization list are not saved unless both the normalization list dialog and the span dialog are confirmed with the OK button.
To create a normalization annotation, it's often necessary to search for the unique identifier (ID) of the intended entry, as IDs are typically just meaningless sequences of characters. The normalization search dialog provides access to two alternative searches, after selecting the desired normalization database:
- entering a query in the query text input field and clicking the Search button (or equivalently, hitting Enter) will use the normalization DB search functionality within brat (shown below)
- clicking on the magnifying glass logo next to the normalization database
selector opens a separate page with
the resource URL (as configured
in
tools.confby the <URL> setting), providing fast access to "native" search functionality that can be used to determine the ID, which can then be copied into the brat dialog.
The search dialog can be used to query the brat normalization DB using approximate string matching, which allows for variation and typos (e.g. "Barak Obama"). The correct entry can be selected and its ID associated with the annotation simply by double-clicking on it.
If you're going to be working on normalization annotation on a brat server administered by someone else, that's all you need to know! If you need to set up a normalization database and configure brat for normalization yourself, read on.
Database setup
Before brat can be used for normalization to a specific resource, it is necessary to create a brat normalization DB for that resource. This can be easily done using tools distributed with brat.
Given a file with the normalization data in the
text-based brat normalization data
format (examples are found in
example-data/normalisation/), a new normalization DB
can be set up simply by running the following command in the brat
root directory:
python tools/norm_db_init.py FILEwhere FILE is the name of the file containing the
normalization data. This will create a brat normalization DB, by
default with the same name as FILE (without filename suffix),
storing the DB in the brat work/ directory.
To see the options for this tool, run
python tools/norm_db_init.py -hFor information on testing a normalization DB using command-line tools, see normalization DB tools.
After creating a normalization DB, it's necessary to edit the
tools.conf file to configure normalization.
Configuration
Normalization configuration is part of the tools.conf
file, where the relevant settings are contained in the
[normalization] section. The full syntax of each line
in this section is as follows:
DBNAME DB:DBPATH, <URL>:HOMEURL, <URLBASE>:ENTRYURL, <UNICODE>:TRUEorFALSEHere, DB, <URL>,
<URLBASE> and <PATH> are
literal strings (they should appear as written here), while
"DBNAME", "DBPATH", "HOMEURL", "ENTRYURL" and "TRUEorFALSE" should be replaced with
specific values appropriate for the database being configured:
DBNAME: sets the database name (e.g. "Wiki", "GO"). The name can be otherwise freely selected, but should not contain characters other than alphanumeric ("a"-"z", "A"-"Z", "0"-"9"), hyphen ("-") and underscore ("_"). This name will be used both in the brat UI and in the annotation file to identify the DB.DB(optional): provides the file system path to the normalization DB data on the server, relative to the brat server root. IfDBparameter isn't set, the system assumes the database can be found in the default location under the givenDBNAME.URL: sets the URL for the home page of the normalization resource (e.g. "http://en.wikipedia.org/wiki/"). Used both to identify the resource more specifically thanDBNAMEand to provide a link in the annotation UI for accessing the resource.URLBASE(optional): sets a URL template (e.g. "http://en.wikipedia.org/?curid=%s") that can be filled in to generate a direct link in the annotation UI to an entry in the normalization resource. The value must contain the characters%sas a placeholder that will be replaced with the ID of the entry.UNICODE(optional): specifies whether the database is created as Unicode or binary. Note that simstring bindings library only handles binary databases. The accepted values are:true,t,1,yes,y,on,false,f,0,no,n,off.
Note that individual collections can have their
own tools.conf files, so different annotation projects
can have different normalization settings.
To use a normalization database in annotation, additionally annotation.conf entity and event specifications need to have a parameter <NORM>:DB1|DB2|..., specifying which databases are relevant to each span type.
After creating a normalization DB and configuring brat to use it, brat is ready for normalization annotation. For information on how to format any dataset for use for brat normalization, see the next section.
Normalization DB file format
To make it easier to set up brat for normalization annotation using new resources, brat defines a simple text-based file format that can be used to import data into the brat normalization system.
Each line in the input file should have the following format:
ID <TAB> TYPE1:LABEL1:STRING1 <TAB> TYPE2:LABEL2:STRING2 [...]Where the ID is the unique ID used in normalization, and the
TYPE:LABEL:STRING triplets
provide various information associated with the ID.
(<TAB> is the literal tab character "\t".)
Each TYPE must be one of the following:
- "name":
STRINGis name or alias - "attr":
STRINGis non-name attribute - "info":
STRINGis non-searchable additional information
Each LABEL provides a human-readable label used in the
normalization UI for the
STRING. LABEL values are not used for querying.
For example, for normalization to Wikipedia, the input could contain lines such as the following:
843 name:Title:A Clockwork Orange attr:Category:book
1659954 name:Title:A Clockwork Orange attr:Category:filmSpecifying that "A Clockwork Orance" is the title of a book and a film, and allowing normalization annotation to differentiate between the two.
Each entry must have at least one name, but all other information is optional. There is no need for any of the fields (or their values) to be unique; for example, the following is a valid entry:
534366 name:Name:Barack Obama name:Name:Obama attr:Category:person attr:Category:US presidentGiven a file in this format, a normalization DB can be created as
described in database setup. A number of example
files in this format are found in
example-data/normalisation/ directory in the brat
installation.
Normalization DB tools
brat provides also some command-line tools for working with
normalization DBs. These are found along with many other tools in
the tools/ tools directory of the brat installation.
The script norm_db_lookup.py can be used to retrieve
the ID and other information stored in a normalization DB for a
given entry name. This tool can be helpful for troubleshooting
normalization DB setup. An example session (user input shown in
blue)
python tools/norm_db_lookup.py Wiki
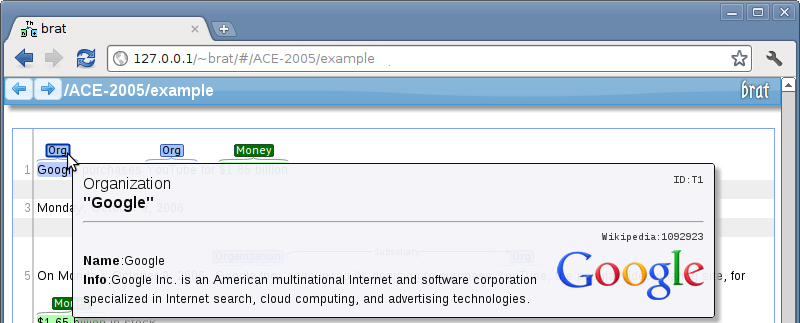
>>> Google
1092923 Name:Google Info:Google Inc. is an American multinational Internet and software corporation [...]
>>> Barak Obama
(no record found for 'Barak Obama')
>>> Barack Obama
534366 Name:Barack Obama Info: Barack Hussein Obama II is the 44th and current President of the United States.
>>> [CRTL-D](Note that this tool does not perform approximate string matching.)
Standoff format for normalization
The brat normalization support involves a new category of annotation in the standoff format used to store brat annotations. (If you don't work directly with the brat standoff format, you can skip these technical details.)
First, brat v1.3 is fully backward compatible with previous versions, and any standoff file created in previous versions of brat is also valid for v1.3. The text file format and the standoff format for annotation primitives defined in previous versions of brat (text-bound annotations, relations, etc.) are also unchanged in v1.3. To understand the basic brat standoff format, see the standoff format description.
To support normalization, v1.3 introduces a new category of
annotation, normalization. Each normalization annotation has
a unique ID and is defined by reference to the ID of the annotation
that the normalization attaches to and a RID:EID pair
identifying the external resource (RID) and the entry
within that resource (EID). Additionally, each
normalization annotation has the type Reference (no
other values for the type are currently defined) and a
human-readable string value for the entry referred to.
The following example shows a normalization annotation attached to the text-bound annotation "T1" (not shown) and associates it with the Wikipedia entry with the Wikipedia ID "534366" ("Barack Obama").
|
As for text-bound annotations, the ID and the text are separated by TAB characters, and other fields (here, "Reference", "T1" and "Wikipedia:534366") by SPACE.
The IDs of normalization annotations follow the general ID conventions in brat and consist of the upper-case character "N" an a number.
Troubleshooting
Normalization configuration fails to take effect
It is necessary to reload the collection for changes to configuration to take effect. This can be done either by navigating to a different collection and back, or simply by reloading the brat page in the browser.
If the issue persists after reloading the collection, it may be
that brat is reading a different tools.conf file than
the one that was edited to configure normalization. For example, if
the collection contains a tools.conf, that
configuration will be used in favor of ones in containing
collections and the brat root directory.
Search fails to return expected results
If brat is showing a specific error message when a search is performed, this message should indicate what the specific issue is.
If search fails to return expected results without giving any
specific error message, first make sure that the data that was used
to create the DB is correctly
formatted. Note that search requires a match against a
name field in the data; it's not enough for the query
string to match e.g. just part of an info field.
The norm_db_lookup.py tool provided with brat can be used to check DB contents from the command line.
")